Устранение проблем производительности системы базы данных может быть непреодолимой задачей. Важно знать, в чем заключается проблема, но еще более важно понимать механизм реагирования системы на определенный запрос. На производительность ЦП сервера базы данных может повлиять ряд факторов: компиляция и перекомпиляция инструкций SQL, отсутствующие индексы, многопоточные операции, проблемы производительности дисков, узкие места со стороны памяти, процедуры обслуживания, действия по извлечению, преобразованию и загрузке и другие факторы. Использование ЦП само по себе не является проблемой — процессор предназначен для выполнения работы. Ключом к оптимальному использованию процессора является обеспечение того, что процессор выполняет необходимую работу, а не тратит время из-за плохо оптимизированного кода или оборудования с низкой производительностью.
Два пути, ведущие в одно место
Если рассматривать в целом, существует два пути определения проблем производительности процессора. Первый заключается в анализе производительности оборудования системы, что помогает определить места для поиска проблемы при переходе ко второму пути, оценке эффективности выполнения сервером запросов. Второй путь обычно более эффективен для определения проблем производительности SQL Server™. Однако если причины проблем производительности запросов точно не известны, всегда следует начинать с анализа производительности системы В конечном счете, обычно вы оказываетесь на обоих путях. Давайте рассмотрим некоторые основные моменты, чтобы можно было перейти к рассмотрению обоих путей.
Технология гиперпоточности
На технологии гиперпоточности стоит остановиться из-за того, как она влияет на SQL Server. Технология гиперпоточности фактически предоставляет операционной системе для одного физического процессора два логических процессора. По сути, технология гиперпоточности арендует время физических процессоров для полного использования возможностей каждого процессора. На веб-узле Intel (intel.com/technology/platform-technology/hyper-threading/index.htm) представлено гораздо более подробное описание работы технологии гиперпоточности.
В системах SQL Server DBMS фактически обрабатывает собственные чрезвычайно эффективные очереди и потоки для операционной системы, поэтому в системах с уже существующей высокой загрузкой процессоров технология гиперпоточности только еще больше перегружает физические ЦП. Когда SQL Server осуществляет постановку в очередь нескольких запросов для работы с несколькими планировщиками, операционной системе приходится переключать контекст потоков команд для обеспечения соответствия выполняемым запросам, даже если два логических процессора принадлежат одному физическому процессору. Если показатель «Контекстных переключений/сек» превышает 5000 для одного физического процессора, следует серьезно рассмотреть вопрос об отключении гиперпоточности в системе и повторном тестировании производительности.
Только в очень редких случаях приложения с высокой загрузкой процессора в SQL Server могут эффективно использовать гиперпоточность. Перед реализацией изменений в рабочих системах необходимо всегда проверять приложения в SQL Server с включенной и выключенной гиперпоточностью.
Основные моменты
Производительность мощного двухъядерного процессора всегда будет превосходить производительность ОЗУ компьютера, скорость которого в свою очередь будет больше скорости подключенного запоминающего устройства. Пропускная способность хорошего процессора приблизительно в шесть раз превосходит пропускную способность лучшей современной памяти DDR2 и приблизительно в два раза превосходит пропускную способность лучшей памяти DDR3. Пропускная способность обычной памяти более чем в 10 раз превышает пропускную способность самых быстрых оптоволоконных приводов. В свою очередь, жесткие диски могут выполнять только ограниченное число операций ввода/вывода в секунду (IOPS), это значение всецело зависит от количества операций поиска в секунду, которое может выполнять привод. Справедливости ради надо сказать, что для удовлетворения всех потребностей в хранении систем баз данных предприятий обычно используется несколько устройств хранения. Сегодня в большинстве установок используются сети хранилищ данных (SAN) на серверах баз данных предприятий или группы RAID большего размера, которые могут минимизировать или устранить проблему процессора дискового ввода-вывода. Важно помнить, что независимо от особенностей установки системы узкие места со стороны дисков и памяти могут повлиять на производительность процессоров.
Из-за различий в скорости ввода-вывода получение данных с диска намного дороже, чем получение данных из памяти. Размер страницы данных в SQL Server – 8 КБ. Блок в SQL Server состоит из восьми страниц размером 8 КБ каждая и соответственно имеет размер 64 КБ. Это важно понимать, поскольку когда SQL Server запрашивает определенную страницу данных с диска, выполняется получение всего блока, в который входит страница данных, а не только этой определенной страницы. Существует ряд причин, делающих это наиболее эффективным для SQL Server, но в данной статье я не будут рассматривать этот вопрос подробно. Получение страницы данных, уже кэшированной из буферного пула, с максимальной производительностью выполняется в течение половины миллисекунды; получение одного блока с диска в оптимальной среде занимает от 2 до 4 миллисекунд. Обычно чтение хорошо работающей исправной дисковой подсистемы занимает от 4 до 10 мс. Получение страницы данных из памяти обычно выполняется от 4 до 20 раз быстрее, чем получение страницы данных с диска.
Когда SQL Server запрашивает страницу данных, он выполняет поиск в буферном кэше в памяти, а затем в дисковой подсистеме. Найдя страницу данных в буферном пуле, процессор получит данные и выполнит необходимые операции. Это называется ошибкой страницы ОЗУ. Ошибки страниц ОЗУ идеальны для SQL Server, поскольку для использования данных, полученных в качестве части запроса, они должны находиться в буферном кэше. Страница данных, не найденная в буферном кэше, должна быть получена из дисковой подсистемы сервера. Необходимость получения операционной системой страницы данных диска называется ошибкой страницы физической памяти.
При согласовании производительности памяти, дисков и ЦП объективно оценить все компоненты помогает общий знаменатель: пропускная способность. Говоря ненаучно, пропускная способность – это максимальный объем данных, который может передавать конечный канал.
Путь 1. Производительность системы
Существует всего несколько способов определения наличия узких мест ЦП на сервере и не очень много возможных причин высокой загрузки процессора. Некоторые из этих проблем можно отследить с помощью системного монитора или сходного средства наблюдения за системой, другие же проблемы можно отследить с помощью профилировщика SQL или сходных средств. Другой способ заключается в использовании команд SQL в Query Analyzer или SQL Server Management Studio (SSMS).
При оценке производительности системы я использую подход «Начните широко, затем анализируйте подробно». Очевидно, исследование проблемных мест возможно только после их определения. После оценки общего использования ЦП с помощью специальной программы, например системного монитора, ее можно использовать для просмотра нескольких очень простых и понятных счетчиков производительности.
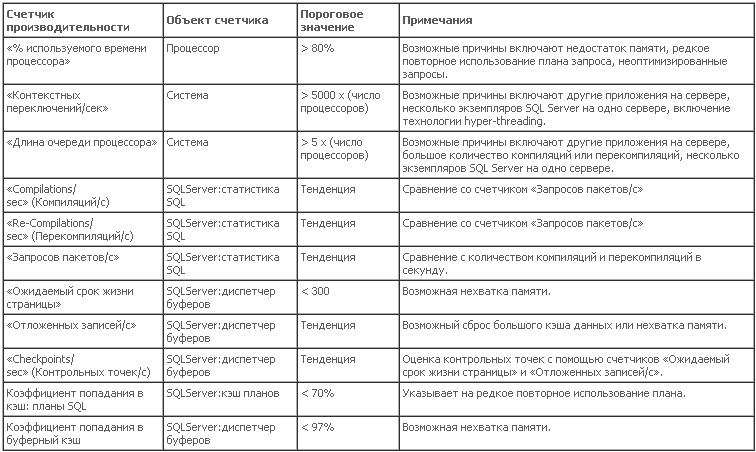
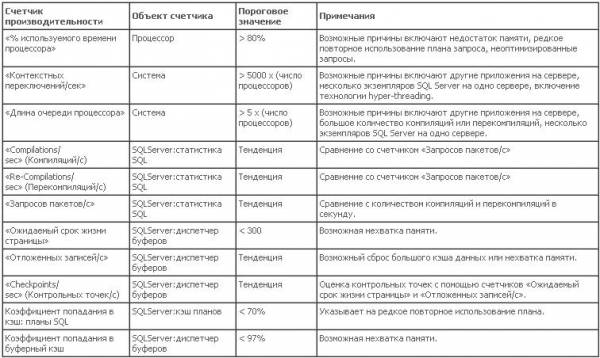
Одним из самых известных счетчиков производительности является счетчик «% загруженности процессора»; во время работы системного монитора этот счетчик выделяется после открытия окна «Add Counter» (Добавление счетчика). Счетчик «% загруженности процессора» отображает время, в течение которого процессоры остаются занятыми при выполнении операций. Как правило, загруженность процессоров считается высокой, когда это значение составляет 80 или более процентов в течение большей части времени работы с максимальной загрузкой. Иногда значение может внезапно повышаться до 100 процентов, даже если сервер работает с загрузкой менее 80 процентов, но это не является неполадкой.
Другим счетчиком, который необходимо использовать, является «Длина очереди процессора», который находится в объекте «Система» системного монитора. Счетчик «Длина очереди процессора» показывает количество потоков, ожидающих выполнения на процессоре. Управление работой SQL Server осуществляется с помощью планировщиков в механизме СУБД, где сервер помещает в очередь и обрабатывает собственные запросы. Поскольку работа SQL Server управляет им самим, он использует только один поток ЦП для каждого логического процессора. Это означает, что в очереди процессора системы, предназначенной для SQL Server, должно находиться минимальное количество потоков. Обычно количество потоков на выделенном сервере SQL Server в пять раз меньше количества физических процессоров, но я считаю, что если количество потоков в два раза превышает количество физических процессоров, это уже является проблемой. На серверах, где кроме СУБД используются и другие приложения, этот счетчик необходимо использовать вместе со счетчиками производительности «% загруженности процессора» и «Контекстных переключений/сек» (переключения контекста будут рассмотрены позже) для определения необходимости перемещения СУБД или приложений на другой сервер.
При возникновении очереди процессора и высокой загрузке ЦП я использую счетчики «Compilations/sec» (Компиляций/с) и «Re-Compilations/sec» (Повторных компиляций/с) объекта производительности «SQL Server: статистика SQL» (см. рис. 1). Компиляция и повторная компиляция планов запросов влияет на загрузку ЦП системы. Значения повторных компиляций должны быть около нуля, но необходимо проверить потоки системы, чтобы определить обычное поведение сервера и допустимое количество компиляций. Не всегда удается избежать повторных компиляций, но можно оптимизировать запросы и хранимые процедуры, чтобы свести к минимуму количество повторных компиляций и использований планов запросов. Сравните эти значения с фактическими поступающими в систему инструкциями SQL с помощью счетчика «Пакетных запросов/с», который также находится в объекте «SQL Server: статистика SQL». Если компиляции и повторные компиляции составляют значительный процент поступающих в систему запросов пакетов, это место необходимо проверить. Иногда разработчики SQL могут не понимать, как и почему их код может влиять на эти типы проблем системных ресурсов. Далее в этой статье я приведу ссылки, которые помогут свести к минимуму действия такого типа.
Рис. 1 Выбор счетчиков для отслеживания
В системном мониторе найдите счетчик производительности «Контекстных переключений/сек» (см. рис. 2).
Рис. 2 Используемые счетчики производительности
Этот счетчик указывает количество получений потоков из планировщиков операционной системы (не из планировщиков SQL) для выполнения операций для других потоков в состоянии ожидания. Часто переключения контекста происходят значительно чаще в системах база данных, использующихся совместно с другими приложениями, например IIS или компонентами сервера приложений сторонних производителей. Для счетчика «Контекстных переключений/сек» я использую пороговое значение приблизительно в 5000 раз большее количества процессоров в сервере. Это значение также может быть высоким в системах с включенной гиперпоточностью и невысокой загрузкой ЦП. Если пороговые значения загрузки ЦП и переключений контекста регулярно превышаются, это говорит о наличии узкого места, связанного с ЦП. Если такие ситуации возникают регулярно, и ваша система устарела, необходимо запланировать приобретение дополнительных или более быстрых процессоров. Дополнительные сведения приведены на боковой панели «Гиперпоточность».
Модуль отложенной записи SQL Server (как он называется в SQL Server 2000) или монитор ресурсов (как он называется в SQL Server 2005) – это другая область для наблюдения при высокой загрузке ЦП. Сброс буфера и кэши процедур могут увеличивать процессорное время через поток ресурсов, называемый монитором ресурсов. Монитор ресурсов – это процесс SQL Server, определяющий страницы для сохранения и страницы для записи из буферного пула на диск. Всем страницам в буфере и кэшах процедур изначально присвоены стоимости, представляющие ресурсы, потребляемые при помещении этой страницы в кэш. Эти значения стоимостей уменьшаются при каждой проверке монитором ресурсов. При необходимости для запроса пространства в кэше страницы удаляются из памяти на основе присвоенных для всех страниц затрат; страницы с самыми низками значениями будут удаляться в первую очередь. Операции монитора ресурсов можно отследить с помощью счетчика производительности «Отложенных записей/с» объекта «SQL Server: диспетчер буферов» системного монитора. Необходимо отследить изменение этого значения, чтобы определить обычное для вашей системы пороговое значение. Обычно этот счетчик используется вместе со счетчиками «Ожидаемый срок жизни страницы» и «Checkpoints/sec» (Контрольных точек/с) для определения наличия нехватки памяти.
Счетчик «Ожидаемый срок жизни страницы» помогает определить наличие нехватки памяти. Счетчик «Ожидаемый срок жизни страницы» показывает длительность нахождения страницы данных в буферном кэше. Общепринятое в отрасли пороговое значение для этого счетчика – 300 секунд. Значение ниже среднего значения в 300 секунд, сохраняющееся в течение длительного времени, свидетельствует о том, что страницы данных удаляются из памяти слишком часто. Это увеличивает объем работы монитора ресурсов, что в свою очередь приводит к увеличению загрузки процессоров. Показания счетчика «Ожидаемый срок жизни страницы» должны оцениваться вместе с показаниями счетчика «Страниц контрольных точек/с». При возникновении в системе контрольной точки «грязные» страницы данных в буферном кэше записываются на диск, вызывая уменьшение значения счетчика «Ожидаемый срок жизни страницы». Процесс «Монитор ресурсов» – это механизм, фактически записывающий эти страницы на диск, поэтому при возникновении контрольных точек также увеличивается значение счетчика «Отложенных записей/с». Если значение счетчика «Ожидаемый срок жизни страницы» увеличивается сразу после выполнения контрольной точки, на это временное явление можно не обращать внимание. С другой стороны, при обнаружении того, что значение счетчика «Ожидаемый срок жизни страницы» регулярно находится ниже порогового значения, велика вероятность, что увеличение объема памяти приведет к устранению проблем и освобождению части ресурсов для ЦП. Все эти счетчики находятся в объекте производительности «SQL Server: диспетчер буферов».
Отслеживание SP
При трассировке приложения SQL Server имеет смысл ознакомиться с используемыми для трассировки хранимыми процедурами. Использование для трассировки графического интерфейса (SQL Server Profiler) может увеличить нагрузку на систему на 15 – 25 процентов. Использование для трассировки хранимых процедур может снизить процент увеличения нагрузки примерно наполовину.
Если мне известно о наличии в системе узких мест и необходимо определить текущие инструкции SQL, являющиеся причинами проблем на сервере, я выполняю приведенный ниже запрос. Этот запрос помогает получить представление об отдельных инструкциях и используемых ими в настоящий момент ресурсах, а также об инструкциях, которые необходимо изучить для повышения производительности. Дополнительные сведения о трассировках SQL приведены на веб-странице msdn2.microsoft.com/ms191006.aspx.
SELECT
substring(text,qs.statement_start_offset/2
,(CASE
WHEN qs.statement_end_offset = -1 THEN len(convert(nvarchar(max), text)) * 2
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2)
,qs.plan_generation_num as recompiles
,qs.execution_count as execution_count
,qs.total_elapsed_time - qs.total_worker_time as total_wait_time
,qs.total_worker_time as cpu_time
,qs.total_logical_reads as reads
,qs.total_logical_writes as writes
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) st
LEFT JOIN sys.dm_exec_requests r
ON qs.sql_handle = r.sql_handle
ORDER BY 3 DESC
Путь 2. Производительность запросов
Планы запросов анализируются, оптимизируются, компилируются и помещаются в кэш процедур при отправке на SQL Server нового запроса. При каждой отправке серверу запроса выполняется проверка кэша процедур для попытки сопоставления плана запроса с запросом. При отсутствии плана запроса SQL Server создает новый план для запроса, что может быть дорогостоящей операцией.
Ниже приведены некоторые важные моменты, касающиеся оптимизации ЦП для T-SQL.
Повторное использование плана запроса
Уменьшение количества компиляций и повторных компиляций
Операции сортировки
Недопустимые соединения
Отсутствующие индексы
Просмотры таблиц/индексов
Использование функций в предложениях SELECT и WHERE
Многопоточные операции
Рассмотрим эти моменты. Обычно SQL Server получает данные из памяти и с диска; работа только с одной страницей данных встречается довольно редко. Гораздо чаше несколько частей приложения работают с записью, выполняют несколько небольших запросов или объединяют таблицы для создания общего представления соответствующих данных. В средах OLAP приложения могут получать миллионы строк из одной или двух таблиц, делая возможными консолидацию, накопление и суммирование данных для региональных ответов о продажах. В подобных случаях возврат данных может измеряться в миллисекундах, если данные находятся в памяти, а получение этих же данных с диска может длиться несколько минут.
Первый пример – это ситуация с большим количеством транзакций, в которой повторное использование плана зависит от приложения. Редкое повторное использование плана обуславливает большое число компиляций инструкций SQL, для чего требуется значительный объем процессорной обработки. Во втором примере высокая загрузка ресурсов может привести к чрезмерной активности системного ЦП, поскольку требуется постоянное удаление существующих данных из буферного кэша для освобождения пространства для новых страниц данных большого объема.
Рассмотрим систему с высокой интенсивностью транзакций, в которой инструкция SQL, подобная показанной ниже, выполняется 2000 раз в течение 15 минут для получения информации о транспортной упаковке. Гипотетически, без повторного использования плана запроса время выполнения одной инструкции составляет около 450 мс. При использовании этого же плана запроса после первого выполнения время выполнения последующего запроса может составлять около 2 мс, а общее время выполнения – около 5 секунд.
USE SHIPPING_DIST01;
SELECT
Container_ID
,Carton_ID
,Product_ID
,ProductCount
,ModifiedDate
FROM Container.Carton
WHERE Carton_ID = 982350144;
Повторное использование плана запроса является критически важным для обеспечения оптимальной производительности в системах с высокой интенсивностью транзакций, что наиболее часто достигается с посредством параметризации запросов или хранимых процедур. Ниже приведено несколько отличных ресурсов с информацией о повторном использовании плана запроса.
Проблемы пакетной компиляции, перекомпиляции и кэширования плана в SQL Server 2005 (microsoft.com/technet/prodtechnol/sql/2005/recomp.mspx)
Оптимизация хранимых процедур SQL Server для предотвращения перекомпиляций (sql-server-performance.com/rd_optimizing_sp_recompiles.asp)
Перекомпиляция запроса в SQL Server 2000 (msdn2.microsoft.com/aa902682.aspx)
Полезным источником обширных сведений являются динамические административные представления (DMV). При высокой загрузке ЦП я использую несколько DMV для определения правильности использования ЦП.
Одним из используемых DMV является sys.dm_os_wait_stats, с помощью которого администраторам баз данных можно предоставить средства определения всех используемых сервером SQL функций и типов ресурсов, а также определить время ожидания системы, связанное с этим ресурсом. Счетчики в этом DMV являются накопительными. Это означает, что для получения ясного представления о ресурсах, которые могут влиять на различные области системы, после проверки данных на предмет наличия неразрешенных проблем прежде всего необходимо выполнить команду DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR). Динамическое административное представление sys.dm_os_wait_stats является эквивалентом команды проверки согласованности базы данных DBCC SQLPERF(WAITSTATS) в SQL Server 2000. Дополнительные сведения о различных типах ожидания приведены в электронной документации по SQL Server на веб-узле msdn2.microsoft.com/ ms179984.aspx.
Важно понимать, что обычно ожидания присутствуют даже при оптимальной работе системы. Необходимо только определить, влияют ли на ожидания ограничения со стороны ЦП. Время ожидания сигналов относительно общего времени ожидания должно быть как можно меньше. Время ожидания ресурса процессора определенным ресурсом может быть определено простым вычитанием времени ожидания сигнала из общего времени ожидания; это значение не должно превышать приблизительно 20 процентов общего времени ожидания.
Динамическое административное представление sys.dm_exec_sessions показывает все открытые сеансы на сервере SQL Server. Это DMV предоставляет обобщенное представление производительности всех сеансов и всех действий, выполненных в каждом сеансе с момента открытия. Сюда ходит общее время ожидания сеанса, общая загрузка ЦП, использование памяти и количество операций чтения и записи. DMV также предоставляет сведения о входе, времени входа, локальном компьютере и времени последнего запроса сеансом сервера SQL Server.
Динамическое административное представление the sys.dm_exec_sessions позволяет определять только активные сеансы, поэтому это одно из первых мест для поиска при высокой загрузке ЦП. Сначала необходимо выполнять проверку сеансов с большим числом ЦП. Определите приложение и пользователя, выполняющего работу, затем перейдите к углубленному анализу. Использование sys.dm_exec_sessions вместе с sys.dm_exec_requests может предоставить большое количество информации, доступной через хранимые процедуры sp_who и sp_who2. При объединении данных с функцией динамического управления sys.exec_sql_text в столбце sql_handle можно получить текущий выполняемый запрос сеанса. Во фрагменте кода на рис. 3 продемонстрировано объединение этих данных для получения сведений о том, что происходит на сервере.
Рис. 3 Определение активности сервера
SELECT es.session_id
,es.program_name
,es.login_name
,es.nt_user_name
,es.login_time
,es.host_name
,es.cpu_time
,es.total_scheduled_time
,es.total_elapsed_time
,es.memory_usage
,es.logical_reads
,es.reads
,es.writes
,st.text
FROM sys.dm_exec_sessions es
LEFT JOIN sys.dm_exec_connections ec
ON es.session_id = ec.session_id
LEFT JOIN sys.dm_exec_requests er
ON es.session_id = er.session_id
OUTER APPLY sys.dm_exec_sql_text (er.sql_handle) st
WHERE es.session_id > 50 -- < 50 system sessions
ORDER BY es.cpu_time DESC
Я считаю, что этот оператор позволяет определить приложения, которым необходимо уделить особое внимание. Когда я сравниваю ЦП, память, логические считывания, операции чтения и записи всех сеансов приложения и определяю, что загрузка ресурсов ЦП гораздо выше загрузки остальных ресурсов, я акцентирую внимание на этих операторах SQL.
Для отслеживания инструкций SQL по журналу для приложения я использую трассы SQL Server. Для этого можно использовать средство SQL Server Profiler или системные хранимые процедуры трассировки, чтобы оценить происходящее. (Дополнительные сведения по этой теме приведены на боковой панели «Трассировка SP».) В программе Profiler необходимо проверить операторы с высокой загрузкой ЦП, предупреждения хэширования и сортировки, промахи в кэше и другие красные флаги. Это позволяет сузить объекты проверки до определенных операторов SQL или периода времени с высокой загрузкой ресурсов. Программа Profiler позволяет отслеживать текст инструкций SQ, планы выполнения, загруженность ЦП, использование памяти, логические считывания, запись, кэширование планов запросов, перекомпиляции, извлечение планов запросов из кэша, промахи в кэше, просмотры таблиц и индексов, отсутствие статистики и множество других событий.
После сбора данных с помощью хранимых процедур sp_trace или средства SQL Server Profiler я обычно использую базу данных, заполненную уже полученными данными трассировки или данными, которые будут получены после установки для трассировки записи в базу данных. Заполнение базы данных уже полученными данными может быть выполнено с помощью системной функции SQL Server с названием fn_trace_getinfo. Преимущество этого подхода заключается в возможности запроса и сортировки данных несколькими способами для определения инструкций SQL, использующих большую часть времени ЦП или имеющих большее количество операций чтения, определения количество перекомпиляций и пр. Вот пример использования этой функции для загрузки таблицы с файлом трассировки Profile. По умолчанию все файлы для этой трассировки будут загружены в порядке их создания:
SELECT * INTO trc_20070401
FROM fn_trace_gettable('S:\Mountpoints\TRC_20070401_1.trc', default);
GO
Заключение
Как показано выше, высокая загрузка ЦП не обязательно свидетельствует о наличии узкого места, связанного с процессором. Высокая загрузка ЦП может также скрывать ряд других узких мест, связанных с приложениями или оборудованием. После определения высокой загрузки ЦП, несмотря на допустимые показания других счетчиков, можно начать поиск причины в системе и найти решение (будь то приобретение дополнительных процессоров или оптимизация кода SQL). Что бы вы ни делали, не сдавайтесь! Приведенные в данной статье советы, а также немного практических материалов и исследований делают оптимизацию загрузки ЦП в SQL Server достижимой задачей.
|