В процессе оптимизации сервера базы данных требуется настройка производительности отдельных запросов. Это так же (а может быть, и более) важно, чем настройка других элементов, влияющих на производительность сервера, например конфигурации аппаратного и программного обеспечения.
Даже если сервер базы данных использует самое мощное аппаратное обеспечение на свете, горсточка плохо себя ведущих запросов может плохо отразиться на его производительности. Фактически, даже один неудачный запрос (иногда их называют «вышедшими из-под контроля») может вызвать серьезное снижение производительности базы данных.
Напротив, тонкая настройка набора наиболее дорогих или часто выполняемых запросов может сильно повысить производительность базы данных. В этой статье я планирую рассмотреть некоторые технологии, которые можно использовать для идентификации или тонкой настройки самых дорогих и плохо работающих запросов к серверу.
Анализ планов выполнения
Обычно при настройке отдельных запросов стоит начать с рассмотрения плана выполнения запроса. В нем описана последовательность физических и логических операций, которые SQL ServerTM использует для выполнения запроса и вывода желаемого набора результатов. План выполнения создает в фазе оптимизации обработки запроса компонент ядра базы данных, который называется оптимизатором запросов, принимая во внимание много различных факторов, например использованные в запросе предикаты поиска, задействованные таблицы и условия объединения, список возвращенных столбцов и наличие полезных индексов, которые можно использовать в качестве эффективных путей доступа к данным.
В сложных запросах количество всех возможных перестановок может быть огромным, поэтому оптимизатор запросов не оценивает все возможности, а пытается найти «подходящий» для данного запроса путь. Дело в том, что найти идеальный план возможно не всегда. Даже если бы это было возможно, стоимость оценки всех возможностей при разработке идеального плана легко перевесила бы весь выигрыш в производительности. С точки зрения администратора базы данных важно понять процесс и его ограничения.
Существует несколько способов извлечения плана выполнения запроса:
В Management Studio есть функции отображения реального и приблизительного плана выполнения, представляющие план в графической форме. Это наиболее удобная возможность непосредственной проверки и, по большому счету, наиболее часто используемый способ отображения и анализа планов выполнения (примеры из этой статьи я буду иллюстрировать графическими планами, созданными именно таким способом).
Различные параметры SET, например, SHOWPLAN_XML и SHOWPLAN_ALL, возвращают план выполнения в виде документа XML, описывающего план в виде специальной схемы, или набора строк с текстовым описанием каждой операции.
Классы событий профайлера SQL Server, например, Showplan XML, позволяют собирать планы выполнения выражений методом трассировки.
Хотя XML-представление плана выполнения не самый удобный для пользователя формат, эта команда позволяет использовать самостоятельно написанные процедуры и служебные программы для анализа, поиска проблем с производительностью и практически оптимальных планов. Представление на базе XML можно сохранить в файл с расширением sqlplan, открывать в Management Studio и создавать графическое представление. Кроме того, эти файлы можно сохранять для последующего анализа без необходимости воспроизводить их каждый раз, как этот анализ понадобится. Это особенно полезно для сравнения планов и выявления возникающих со временем изменений.
Оценка стоимости выполнения
Первое, что нужно понять — это как генерируются планы выполнения. SQL Server использует оптимизатор запроса на основе стоимости, то есть пытается создать план выполнения с минимальной оценочной стоимостью. Оценка производится на основе статистики распределения доступных оптимизатору на момент проверки каждой использованной в запросе таблицы данных. Если такой статистики нет или она уже устарела, оптимизатору запроса не хватит необходимой информации и оценка, скорее всего, окажется неточной. В таких случаях оптимизатор переоценит или недооценит стоимость выполнения различных планов и выберет не самый оптимальный.
Существует несколько распространенных, но неверных представлений о приблизительной стоимости выполнения. Особенно часто считается, что приблизительная стоимость выполнения является хорошим показателем того, сколько времени займет выполнение запроса и что эта оценка позволяет отличить хорошие планы от плохих. Это неверно. Во-первых, есть много документов касающихся того, в каких единицах выражается приблизительная стоимость и имеют ли они непосредственное отношение ко времени выполнения. Во-вторых, поскольку значение это приблизительно и может оказаться ошибочным, планы с большими оценочными затратами иногда оказываются значительно эффективнее с точки зрения ЦП, ввода/вывода и времени выполнения, несмотря на предположительно высокую стоимость. Это часто случается с запросами, где задействованы табличные переменные. Поскольку статистики по ним не существует, оптимизатор запросов часто предполагает, что в таблице есть всего одна строка, хотя их во много раз больше. Соответственно, оптимизатор выберет план на основе неточной оценки. Это значит, что при сравнении планов выполнения запросов не следует полагаться только на приблизительную стоимость. Включите в анализ параметры STATISTICS I/O и STATISTICS TIME, чтобы определить истинную стоимость выполнения в терминал ввода/вывода и времени работы ЦП.
Здесь стоит упомянуть об особом типе плана выполнения, который называется параллельным планом. Такой план можно выбрать при отправке на сервер с несколькими ЦП запроса, поддающегося параллелизации (В принципе, оптимизатор запроса рассматривает использование параллельного плана только в том случае, если стоимость запроса превышает определенное настраиваемое значение.) Из-за дополнительных расходов на управление несколькими параллельными процессами выполнения, связанными с распределением заданий, выполнением синхронизации и сведением результатов, параллельные планы обходятся дороже, что отражает их приблизительная стоимость. Тогда чем же они предпочтительнее более дешевых, не параллельных планов? Благодаря использованию вычислительной мощности нескольких ЦП параллельные планы обычно выдают результат быстрее стандартных. В зависимости от конкретного сценария (включая такие переменные, как доступность ресурсов с параллельной нагрузкой других запросов) эта ситуации для кого-то может оказаться желательной. Если это ваш случай, нужно будет указать, какие из запросов можно выполнять по параллельному плану и сколько ЦП может задействовать каждый. Для этого нужно настроить максимальную степень параллелизма на уровне сервера и при необходимости настроить обход этого правила на уровне отдельных запросов с помощью параметра OPTION (MAXDOP n).
Анализ плана выполнения
Теперь рассмотрим простой запрос, его план выполнения и некоторые способы повышения производительности. Предположим, что я выполняю этот запрос в Management Studio с включенным параметром включения реального плана выполнения в примере базы данных Adventure Works SQL Server 2005:
SELECT c.CustomerID, SUM(LineTotal)
FROM Sales.SalesOrderDetail od
JOIN Sales.SalesOrderHeader oh
ON od.SalesOrderID=oh.SalesOrderID
JOIN Sales.Customer c ON oh.CustomerID=c.CustomerID
GROUP BY c.CustomerID
В итоге я вижу план выполнения, изображенный на рис. 1. Этот простой запрос вычисляет общее количество заказов, размещенных каждым клиентом в базе данных Adventure Works. Глядя на этот план, вы видите, как ядро базы данных обрабатывает запросы и выдает результат. Графические планы выполнения читаются сверху вниз, справа налево. Каждый значок соответствует выполненной логической или физической операции, а стрелки — потокам данных между операциями. Толщина стрелок соответствует количеству переданных строк (чем толще, тем больше). Если поместить курсор на один из значков оператора, появится желтая подсказка (такая, как на рис. 2) со сведениями о данной операции.
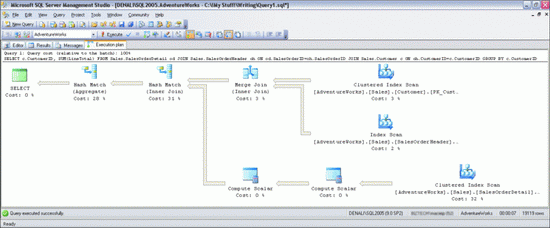
Рис. 1 Пример плана выполнения

Рис. 2 Сведения об операции
Глядя на операторы, можно анализировать последовательность выполненных этапов:
Ядро базы данных выполняет операцию сканирования кластеризированных индексов с таблицей Sales.Customer и возвращает столбец CustomerID со всеми строками из этой таблицы.
Затем оно выполняет сканирование индексов (не кластеризированных) над одним из индексов из таблицы Sales.SalesOrderHeader. Это индекс столбца CustomerID, но подразумевается, что в него входит столбец SalesOrderID (ключ кластеризации таблицы). Сканирование возвращает значения обоих столбцов.
Результаты обоих сеансов сканирования объединяются в столбце CustomerID с помощью физического оператора слияния (это один из трех возможных физических способов выполнения операции логического объединения. Операция выполняется быстро, но входные данные приходится сортировать в объединенном столбце. В данном случае обе операции сканирования уже возвратили строки, рассортированные в столбце CustomerID, так что дополнительную сортировку выполнять не нужно).
Затем ядро базы данных выполняет сканирование кластеризированного индекса в таблице Sales.SalesOrderDetail, извлекая значения четырех столбцов (SalesOrderID, OrderQty, UnitPrice и UnitPriceDiscount) из всех строк таблицы (предполагалось, что возвращено будет 123,317 строк. Как видно из свойств Estimated Number of и and Actual Number of Rows на рис. 2, получилось именно это число, так что оценка оказалась очень точной).
Строки, полученные при сканировании кластеризованного индекса, передаются оператору вычисления стоимости, умноженной на коэффициент, чтобы вычислить значение столбца LineTotal для каждой строки на основе столбцов OrderQty, UnitPrice и UnitPriceDiscount, упомянутых в формуле.
Второй оператор вычисления стоимости, умноженной на коэффициент, применяет к результату предыдущего вычисления функцию ISNULL, как и предполагает формула вычисленного столбца. Он завершает вычисление в столбце LineTotal и возвращает его следующему оператору вместе со столбцом SalesOrderID.
Вывод оператора слияния с этапа 3 объединяется с выводом оператора стоимости, умноженной на коэффициент с этапа 6 и использованием физического оператора совпадения значений хэша.
Затем к группе строк, возвращенных оператором слияния по значению столбца CustomerID и вычисленному сводному значению SUM столбца LineTotal применяется другой оператор совпадения значений хэша.
Последний узел, SELECT — это не физический или логический оператор, а местозаполнитель, соответствующий сводным результатам запроса и стоимости.
В созданном на моем ноутбуке плане выполнения приблизительная стоимость равнялась 3,31365 (как видно на рис. 3). При выполнении с включенной функцией STATISTICS I/O ON отчет по запросу содержал упоминание о 1,388 логических операциях чтения из трех задействованных таблиц. Процентное значение под каждым оператором — это его стоимость в процентах от общей приблизительной стоимости всего плана. На плане на рис. 1 видно, что большая часть общей стоимости связана со следующими тремя операторами: сканирование кластеризованного индекса таблицы Sales.SalesOrderDetail и два оператора совпадения значений хэша. Перед тем как приступить к оптимизации, хотелось отметить одно очень простое изменение в моем запросе, которое позволило полностью устранить два оператора.

Рис. 3 Общая приблизительная стоимость выполнения запроса
Поскольку я возвращал из таблицы Sales.Customer только столбец CustomerID, и тот же столбец включен в таблицу Sales.SalesOrderHeaderTable в качестве внешнего ключа, я могу полностью исключить из запроса таблицу Customer без изменения логического значения или результата нашего запроса. Для этого используется следующий код:
SELECT oh.CustomerID, SUM(LineTotal)
FROM Sales.SalesOrderDetail od JOIN Sales.SalesOrderHeader oh
ON od.SalesOrderID=oh.SalesOrderID
GROUP BY oh.CustomerID
Получился другой план выполнения, который изображен на рис. 4.

Рис. 4 План выполнения после устранения из запроса таблицы Customer
Полностью устранены две операции — сканирование кластеризированного индекса таблицы Customer и слияние Customer и SalesOrderHeader, а совпадение значений хэша заменено на куда более эффективную операцию слияния. При этом для слияния таблиц SalesOrderHeader и SalesOrderDetail нужно вернуть строки обеих таблиц, рассортированные по общему столбцу SalesOrderID. Для этого оптимизатор кластера выполнил сканирование кластеризованного индекса таблицы SalesOrderHeader вместо того, чтобы использовать сканирование некластеризованного индекса, который был бы дешевле с точки зрения ввода/вывода. Это хороший пример практического применения оптимизатора запроса, поскольку экономия, получающаяся при изменении физического способа слияния, оказалась больше дополнительной стоимости ввода/вывода при сканировании кластеризованного индекса. Оптимизатор запроса выбрал получившуюся комбинацию операторов, поскольку она дает минимально возможную примерную стоимость выполнения. На моем компьютере, несмотря на то, что количество логических считываний возросло (до 1,941), временные затраты ЦП стали меньше, и приблизительная стоимость выполнения данного запроса упала на 13 процентов (2,89548).
Предположим, что я хочу еще улучшить производительность запроса. Я обратил внимание на сканирование кластеризованного индекса таблицы SalesOrderHeader, которое теперь является самым дорогим оператором плана выполнения. Поскольку для выполнения запроса нужно всего два столбца, можно создать некластеризованный индекс, где содержатся только эти два столбца. Таким образом, вместо сканирования всей таблицы можно будет просканировать индекс гораздо меньшего размера. Определение индекса может выглядеть примерно так:
CREATE INDEX IDX_OrderDetail_OrderID_TotalLine
ON Sales.SalesOrderDetail (SalesOrderID) INCLUDE (LineTotal)
Обратите внимание, что в созданном индексе есть вычисленный столбец. Это возможно не всегда — все зависит от определения такого столбца.
Создав этот индекс и выполнив тот же запрос, я получил новый план, который изображен на рис. 5.

Рис. 5 Оптимизированный план выполнения
Сканирование кластеризованного индекса таблицы SalesOrderDetail заменено некластеризованным сканированием с заметно меньшими затратами на ввод/вывод. Кроме того, я исключил один из операторов вычисления стоимости, умноженной на коэффициент, поскольку в моем индексе уже есть вычисленное значение столбца LineTotal. Теперь приблизительная стоимость плана выполнения составляет 2,28112 и при выполнении запроса производится 1,125 логических считываний.
Упражнение. Запрос заказа покупателя
Вопрос. Вот пример запроса заказа покупателя. Попробуйте получить определение индекса: выясните, наличие каких столбцов превратит его в индекс покрытия данного запроса и повлияет ли порядок столбцов на производительность.
Ответ. Я предложил рассчитать оптимальный индекс покрытия для создания таблицы Sales.SalesOrderHeader на примере запроса из моей статьи. При этом нужно в первую очередь отметить, что запрос использует только два столбца из таблицы: CustomerID и SalesOrderID. Если вы внимательно прочли эту статью, то заметили, что в случае с таблицей SalesOrderHeader индекс покрытия запроса уже существует, это индекс CustomerID, который косвенно содержит столбец SalesOrderID, являющийся ключом кластеризации таблицы.
Конечно, я объяснял и то, почему оптимизатор запроса не стал использовать этот индекс. Да, можно заставить оптимизатор запроса использовать этот индекс, но это решение было бы менее эффективным, чем существующий план с операторами сканирования кластеризованного индекса и слияния. Дело в том, что оптимизатор запроса пришлось бы принудить либо выполнить дополнительную операцию сортировки, необходимую для использования слияния, либо откатиться назад, к использованию менее эффективного оператора совпадения значений хэша. В обоих вариантах приблизительная стоимость выполнения выше, чем в существующем плане (версия с оператором сортировки работала бы особенно плохо), поэтому оптимизатор запроса не будет их использовать без принуждения. Итак, в данной ситуации лучше сканирования кластеризованного индекса будет работать только некластеризованный индекс в столбцах SalesOrderID, CustomerID. При этом нужно отметить, что столбцы должны идти именно в таком порядке:
CREATE INDEX IDX_OrderHeader_SalesOrderID_CustomerID
ON Sales.SalesOrderHeader (SalesOrderID, CustomerID)
Если вы создадите этот индекс, в плане выполнения будет использовано не сканирование кластеризованного индекса, а сканирование индекса. Разница существенная. В данном случае некластеризованный индекс, который содержит только два столбца, заметно меньше всей таблицы в виде кластеризованного индекса. Соответственно, при считывании нужных данных будет меньше задействован ввод/вывод.
Также этот пример показывает, что порядок столбцов в вашем индексе может существенно повлиять на его эффективность для оптимизатора запросов. Создавая индексы с несколькими столбцами, обязательно имейте это в виду.
Индекс покрытия
Индекс, созданный из таблицы SalesOrderDetail, представляет собой так называемый «индекс покрытия». Это некластеризованный индекс, где содержатся все столбцы, необходимые для выполнения запроса. Он устраняет необходимость сканирования всей таблицы с помощью операторов сканирования таблицы или кластеризованного индекса. По сути индекс представляет собой уменьшенную копию таблицы, где содержится подмножество ее столбцов. В индекс включаются только столбцы, которые необходимы для ответа на запрос или запросы, то есть только то, что «покрывает» запрос.
Создание индексов покрытия наиболее частых запросов — один из самых простых и распространенных способов тонкой настройки запроса. Особенно хорошо он работает в ситуациях, когда в таблице несколько столбцов, но запросы часто ссылаются только на некоторые из них. Создав один или несколько индексов покрытия, можно значительно повысить производительность соответствующих запросов, так как они будут обращаться к заметно меньшему количеству данных и, соответственно, количество вводов/выводов сократится. Тем не менее, поддержка дополнительных индексов в процессе модификации данных (операторы INSERT, UPDATE и DELETE) подразумевает некоторые расходы. Следует четко определить, оправдывает ли увеличение производительности эти дополнительные расходы. При этом учтите характеристики своей среды и соотношение количества запросов SELECT и изменений данных.
Не бойтесь создавать индексы с несколькими столбцами. Они бывают значительно полезнее индексов с одним столбцом, и оптимизатор запросов чаще их использует для покрытия запроса. Большинство индексов покрытия содержит несколько столбцов.
С моим примером запроса можно сделать еще кое-что. Создав индекс покрытия таблицы SalesOrderHeader, можно дополнительно оптимизировать запрос. При этом будет использовано сканирование некластеризованного индекса вместо кластеризованного. Предлагаю вам выполнить это упражнение самостоятельно. Попробуйте получить определение индекса: выясните, наличие каких столбцов превратит его в индекс покрытия данного запроса и повлияет ли порядок столбцов на производительность. Решение см. в боковой панели "Упражнение. Запрос заказа покупателя".
Индексированные представления
Если выполнение моего примера запроса очень важно, я могут пойти немного дальше и создать индексированное представление, в котором физически хранятся материализованные результаты запроса. При создании индексированных представлений существуют некоторые предварительные условия и ограничения, но если их удастся использовать, производительность сильно повысится. Обратите внимание, что расходы на обслуживание индексированных представлений выше, чем у обычных индексов. Их нужно использовать с осторожностью. В данном случае определение индекса выглядит примерно так:
CREATE VIEW vTotalCustomerOrders
WITH SCHEMABINDING
AS
SELECT oh.CustomerID, SUM(LineTotal) AS OrdersTotalAmt, COUNT_BIG(*) AS TotalOrderLines
FROM Sales.SalesOrderDetail od
JOIN Sales.SalesOrderHeader oh
ON od.SalesOrderID=oh.SalesOrderID
GROUP BY oh.CustomerID
Обратите внимание на параметр WITH SCHEMABINDING, без которого невозможно создать индекс такого представления, и функцию COUNT_BIG(*), которая потребуется в том случае, если в нашем определении индекса содержится обобщенная функция (в данном случае SUM). Создав это представление, я могу создать и индекс:
CREATE UNIQUE CLUSTERED INDEX CIX_vTotalCustomerOrders_CustomerID
ON vTotalCustomerOrders(CustomerID)
При создании этого индекса результат запроса, включенного в определение представления, материализуется и физически сохраняется на указанном диске. Обратите внимание, что все операции модификации данных исходной таблицы автоматически обновляют значения представления на основе определения.
Если перезапустить запрос, то результат будет зависеть от используемой версии SQL Server. В версиях Enterprise или Developer оптимизатор автоматически сравнит запрос с определением индексированного представления и использует это представление, вместо того чтобы обращаться к исходной таблице. На рис. 6 приведен пример получившегося плана выполнения. Он состоит из одной-единственной операции — сканирования кластеризованного индекса, который я создал на основе представления. Приблизительная стоимость выполнения составляет всего 0,09023 и при выполнении запроса производится 92 логических считывания.

Рис. 6 План выполнения при использовании индексированного представления
Это индексированное представление можно создавать и использовать и в других версиях SQL Server, но для получения аналогичного эффекта необходимо изменить запрос и добавить прямую ссылку на представление с помощью подсказки NOEXPAND, примерно так:
SELECT CustomerID, OrdersTotalAmt
FROM vTotalCustomerOrders WITH (NOEXPAND)
Как видите, правильно использованные индексированные представления могут оказаться очень мощными орудиями. Лучше всего их использовать в оптимизированных запросах, выполняющих агрегирование больших объемов данных. В версии Enterprise можно усовершенствовать много запросов, не изменяя кода.
Поиск запросов, нуждающихся в настройке
Как я определяют, что запрос стоит настроить? Я ищу часто выполняемые запросы, возможно, с невысокой стоимостью выполнения в отдельном случае, но в целом более дорогие, чем крупные, но редко встречающиеся запросы. Это не значит, что последние настраивать не нужно. Я просто считаю, что для начала нужно сосредоточиться на более частых запросах. Так как же их найти?
К сожалению, самый надежный метод довольно сложен и предусматривает отслеживание всех выполненных запросов к серверу с последующий группировкой по подписям. При этом текст запроса с реальными значениями параметров заменяется на замещающий текст, который позволяет выбрать однотипные запросы с разными значениями. Подписи запроса создать тяжело, так что это сложный процесс. Ицик Бен-Ган (Itzik Ben-Gan) описывает решение с использованием пользовательских функций в среде CLR и регулярных выражений в своей книге «Microsoft SQL Server 2005 изнутри: запросы T-SQL».
Существует еще один метод, куда более простой, но не столь надежный. Можно положиться на статистику всех запросов, которая хранится в кэше плана выполнения, и опросить их с использованием динамических административных представлений. На рисунке 7 есть пример запроса текста и плана выполнения 20 запросов из кэша, у которых общее количество логических считываний оказалось максимальным. С помощью этого запроса очень удобно быстро находить запросы с максимальным количеством логических считываний, но есть и некоторые ограничения. Он отображает только запросы с планами, кэшированными на момент запуска. Не кэшированные объекты не отображаются.
Рис. 7 Поиск 20 самых дорогих с точки зрения ввода/вывода при считывании запросов.
SELECT TOP 20 SUBSTRING(qt.text, (qs.statement_start_offset/2)+1,
((CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(qt.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2)+1),
qs.execution_count,
qs.total_logical_reads, qs.last_logical_reads,
qs.min_logical_reads, qs.max_logical_reads,
qs.total_elapsed_time, qs.last_elapsed_time,
qs.min_elapsed_time, qs.max_elapsed_time,
qs.last_execution_time,
qp.query_plan
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp
WHERE qt.encrypted=0
ORDER BY qs.total_logical_reads DESC
Обнаружив запросы с плохой производительностью, рассмотрите их планы и найдите способы оптимизации с помощью технологий индексирования, которые я описал в этой статье. Вы не зря потратите время, если добьетесь успеха.
Удачной настройки!
|
