Для разработчиков одной из сложных проблем в SQL Server является отслеживание того, какие данные изменились в базе. Еще более серьезной задачей является создание простого решения, которое не наносит серьезного удара по производительности рабочих нагрузок и несложно в создании, реализации и управлении. Так зачем идти на все эти заботы ради отслеживания изменений? Действительно ли отслеживание изменений стоит всех этих усилий? Двумя часто цитируемыми примерами являются поддержка обновлений в хранилище данных и поддержка синхронизации гетерогенных, изредка подключаемых систем.
В хранилище данных обычно как-либо представлены таблицы из базы данных оперативной обработки транзакций (OLTP), но схемы таблиц могут существенно отличаться. Это означает необходимость процесса извлечения, преобразования и загрузки данных (extract, transform, load – ETL), перемещающего данные из базы данных OLTP в хранилище данных.
Я могу себе представить три возможных способа выполнить эту задачу. Первый – это периодическое обновление всего хранилища данных. Он очевидно непрактичен для больших объемов данных, а также означает, что обновления хранилища данных не непрерывны. Второй состоит в использовании схемы секционирования в базе данных OLTP, чтобы позволить процессу ETL работать лишь над данными, появившимися со времени предыдущего процесса ETL. Этот метод работает только для вставки данных, а не их обновления или удаления и требует сложного механизма для управления определением границ разделов и переключения разделов. Третий метод – отслеживать изменения в данных OLTP и выполнять процесс ETL лишь на измененных данных. Этот метод наиболее эффективен в плане объема данных.
Мобильные устройства вездесущи в современной бизнес-среде, а это значит, что работа с изредка подключаемыми системами обязательна. С точки зрения систем баз данных проблема состоит в эффективном обновлении хранилища данных на устройстве, которое подключается нечасто, особенно если само хранилище маленькое и радикально отличается по схеме от основной базы данных.
Рассмотрим мобильного продавца услуг, ответственного за часть очень большого каталога продуктов. Каждую ночь этот продавец подключает свое карманное устройство к основной базе данных, чтобы загрузить последние данные – все изменения в этой части каталога продуктов, упрощенные для хранения на карманном устройстве. Передача данных должна быть настолько эффективна, насколько возможно.
Теперь система базы данных может подготовить всю нужную часть каталога продуктов для загрузки на устройство, а устройство – загружать ее. Другими словами, все данные загружаются при каждом подключении устройства, даже если они не менялись. Очевидно, что это довольно неэффективный подход.
Другой подход – заставить базу данных отслеживать изменения в нужной части каталога продуктов. Тогда карманное устройство при подключении запрашивает данные, изменившиеся с момента последнего подключения. В данном решении системе базы данных нужно подготовить лишь часть данных, и загрузка настолько эффективна, насколько возможно.
Другой причиной для отслеживания изменений является поддержка аудита, что важно в наши дни. Аудит отслеживает вносимые изменения, а также то, когда произошло изменение и кто его выполнил. Это безусловно переносит дело на новый уровень, с жесткими ограничениями относительно устойчивости, безопасности и верности законченного журнала аудита.
Технологии, которые были разработаны для отслеживания изменений данных в SQL Server 2008, не предназначались для поддержки аудита, однако SQL Server 2008 предлагает новый компонент, именуемый подсистемой аудита SQL Server, предназначенный специально для аудита. Рик Бихэм (Rick Byham) рассказывал о компоненте подсистемы аудита SQL Server Audit в своей статье "SQL Server 2008: Security" «SQL Server 2008: Безопасность», в апрельском выпуске журнала TechNet Magazine за 2008 год (доступен по адресу technet.microsoft.com/magazine/cc434691).
Как можно видеть, существует ряд убедительных причин отслеживать изменения в данных. Следовательно, важный вопрос состоит в том, как это делать лучше всего.
Как отслеживать изменения в SQL Server 2005
В случае SQL Server 2005 (и предыдущих версий SQL Server) простого, фиксированного решения нет. Так что для этих платформ разработчикам приходится создавать собственные решения под свои приложения, обычно включающие столбцы временных меток, триггеры DML (языка манипулирования данными ) и дополнительные таблицы. Однако эти решения предоставляют ряд потенциальных проблем. Например:
Добавление столбцов временных меток заставляет измениться схему таблицы (с возможными эффектами домино в сохраненных процедурах и прочем коде).
Триггер DML неявно является частью транзакции, содержащей DML, которой он инициируется, так что его время исполнения увеличит длину транзакции. Чем сложнее триггер, тем больше времени у него уйдет на исполнение и тем выше будет негативный эффект для производительности рабочей нагрузки. Триггерам DML, используемым для отслеживания изменений, необходимо обработать вставленные и измененные таблицы, чтобы собрать все изменения и затем вставить их в другую таблицу отслеживания.
Таблица отслеживания должна управляться тем или иным образом, чтобы избежать ее неконтролируемого разрастания, которое может потребовать создания чего-то вроде задания агента для периодического отсева старых данных.
Более простые способы отслеживания изменений в SQL Server 2008
SQL Server 2008 представляет две новых технологии, намного упрощающие отслеживание изменений в данных: отслеживание изменений и сбор данных изменений. Обе функции отслеживают изменившиеся данные (а также используют операции вставки, обновления и удаления, чтобы проследить, как именно изменились данные) и устраняют нужду в пользовательских решениях. За исключением этих сходств механизмы этих функций и объекты их отслеживания на деле довольно различны.
Сбор данных изменений использует асинхронный механизм, отслеживающий все изменения, происходящие в таблице (или определенном наборе столбцов в таблице), включая сами значения столбцов. Он разработан для ситуаций, подобных описанному мною ранее процессу хранилища данных ETL.
Рис. 1 иллюстрирует потребление данных изменений через временные интервалы. Механизм сбора данных изменений извлекает измененные данные в набор таблиц, с последними изменениями на верху таблицы. Процесс ETL может затем запросить у таблиц, содержащих данные изменений, все изменения, произошедшие за определенный временной период. Этот механизм позволяет процессу ETL ограничить объем данных, который должен быть потреблен в каждом пакете.
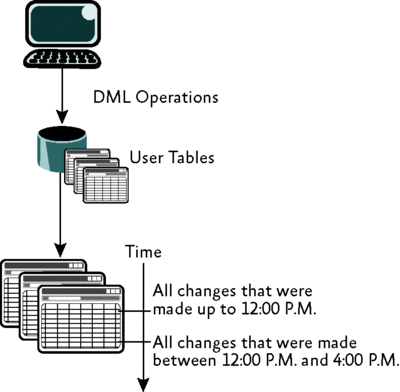
Рис. 1. Данные истории изменений потребляются через временные интервалы
Отслеживание изменений, с другой стороны, использует синхронный механизм, отслеживающий только изменение определенной строки в таблице (и, при желании, список изменившихся столбцов). Это разработано как ответ на проблемы, вроде описанного мною выше случая с изредка подключающейся системой. Этот подход проиллюстрирован на рис. 2.
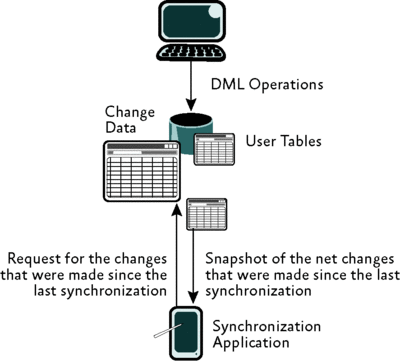
Рис. 2. Использование данных отслеживания изменений изредка подключающейся системой
Обе функции увеличивают объем ввода/вывода и число записей в журнал, но это также верно и для пользовательских решений – данные изменений нужно где-то хранить. Принципиальное различие этих функций от пользовательского решения в том, что таблицы, используемые для хранения данных изменений, должны быть в той же базе данных, что и отслеживаемые таблицы. Это значит, что все данные изменений будут включены в резервные копии и затем переданы по сети, путем доставки журналов или зеркального отражения баз данных.
В плане разработки две эти функции должны существенно уменьшить сложность отслеживания изменений. Ни одна из них не требует изменений схемы или триггеров. Обе имеют настраиваемые, автоматические процессы очистки, сортируют изменения по времени завершения транзакций и предоставляют встроенные функции для извлечения информации об изменениях.
С точки зрения управления у каждого из подходов есть свои «за» и «против». Как и в случае с любой технологией, существует масса информации, которую необходимо усвоить, прежде чем браться за разработку и развертывание решений, использующих эти функции. В оставшейся части статьи я дам обзор обеих этих функций, касаясь того, как они работают и практических моментов, которые следует обдумать, перед использованием их в рабочей среде.
Как работает сбор данных изменений
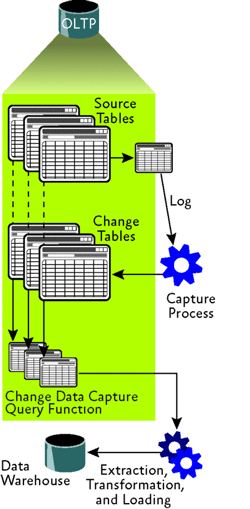
Сбор данных изменений в процессе транзакций не делает ничего, что изменяло бы отслеживаемую таблицу. Вместо этого операции вставки, записи и удаления, записываются в журнал транзакций как обычно и периодически собираются из журнала. Сбор выполняется задачей чтения журнала агента SQL, и собранные операции сохраняются в отдельной таблице, именуемой таблицей изменений. В какой-либо последующий момент таблицу изменений можно запросить, чтобы получить данные изменений, используя одну из двух функций. Комбинация таблицы изменений и двух функций называется экземпляром сбора. Рис. 3 показывает поток данных, использующий сбор данных изменений для управления процессом ETL хранилища данных.
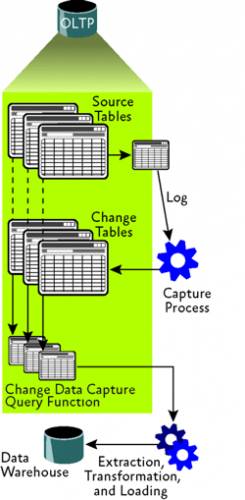
Включения сбора данных изменений – процесс из двух частей. Сперва член фиксированной серверной роли администратора системы должен включить сбор данных изменений для базы данных, используя sys.sp_cdc_enable_db. Затем, член фиксированной серверной роли db_owner («владельца базы данных») должен включить сбор данных изменений для конкретной таблицы, используя sys.sp_cdc_enable_table. Эти требования к безопасности вызваны потенциалом повышенного использования места на диске при неверной настройке сбора данных изменений. Понятно, почему владелец таблицы не может сам включить эту функцию и преподнести администратору базы данных сюрприз в виде повышенного использования диска.
Когда для базы данных включается сбор данных изменений, к базе данных кое-что добавляется, включая схему (именуемую cdc), некоторые таблицы метаданных и триггер для записи событий языка определения данных (Data Definition Language – DDL). (Одна из возможностей, которая мне кажется замечательной – заброс списка изменения DDL в таблицу.)
Включение сбора данных изменений также создает экземпляр сбора для таблицы – таблицу изменений и до двух функций, для возвращения данных изменений. Имя таблицы изменений идентично имени экземпляра сбора, с добавленным _CT. Первая функция создается всегда и используется для возвращения данных изменений из таблицы изменений. Вторая функция создается, если указано допускать итоговые изменения. Это значит, что возвращается лишь финальный результат всех собранных изменений, без всех промежуточных изменений, возвращаемых первой функцией. Имена двух функций это, соответственно, fn_cdc_get_all_changes_ и fn_cdc_get_net_changes_, с добавленным именем экземпляра сбора. Отметьте, что (подобно функции отслеживания изменений) эта функция требует, чтобы у таблицы имелся основной ключ или иной уникальный индекс.
При работе с первой таблицей в базе данных, чтобы включить сбор данных изменений, можно создать две задачи агента SQL: задачу сбора и задачу очистки. Я говорю «можно», поскольку задача сбора идентична используемой для сбора транзакций в транзакционной репликации. Если транзакционная репликация уже настроена, то будет создана только задача очистки и существующая задача чтения журнала будет также использована как задача сбора. Это хорошо тем, что наличие двух задач чтения журнала очень быстро приведет к проблемам конфликтов с журналом и, следовательно, проблемам производительности. Так или иначе, агент SQL должен работать для использования сбора данных изменений.
Логика внутри средства чтения журнала автоматически справляется с включением и выключением таблиц для сбора данных изменений и изменяет собранное из журнала транзакций соответственно. Один важный момент, который следует заметить здесь, состоит в том, что после включения сбора данных журнал транзакций ведет себя точно так же, как в случае репликации транзакций – журнал нельзя обрезать, пока средство чтения журнала не обработало его. Это значит, что операция контрольной точки, даже в режиме восстановления SIMPLE, не обрежет журнал, если он уже не был обработан средством чтения журнала.
Кроме того, если модель восстановления BULK_LOGGED используется для уменьшения числа записей в журнал, сбор данных заставит записывать в журнал все, кроме операций создания/сброса/восстановления индекса. Если вы никогда не сталкивались с таким поведением, имейте в виду, что оно может вызвать проблемы с размером журнала транзакций, особенно если параметры по умолчанию задачи сбора изменены, чтобы обрабатывать журнал менее часто.
По умолчанию задача сбора работает непрерывно, проверяя журнал каждые пять секунд и обрабатывая максимум 500 транзакций из журнала. По умолчанию работа очистки выполняется каждый день в два часа ночи и удаляет все записи изменения данных, которым больше трех дней из таблиц изменений. Эти параметры можно изменить, используя процедуру sys.sp_cdc_change_job после чего изменения не вступят в силу, пока не перезапустить задачи, используя sys.sp_cdc_stop_job and sys.sp_cdc_start_job.
Несмотря на то, что процесс чтения журнала обычно не будет иметь большого эффекта на производительность системы, на сильно загруженных системах OLTP, с большими объемами изменяющихся данных возможно возникновение конфликтов на журнале транзакций из-за добавления всего лишь одного процесса чтения журнала. Сам конфликт будет вызван необходимостью для головок жесткого диска перемещаться назад и вперед между точкой, в которую транзакции записывают журнал, и точкой, в котором он считывается процессом средства чтения журнала. В этом случае может быть необходимо изменить частоту работы задачи сбора, чтобы производительность OLTP не страдала. Это, однако, создает классический конфликт между пространством на диске и производительностью – журнал продолжит расти, пока задача сбора не обработает его.
Та же проблема возникает при изменении частоты работы задачи очистки или изменении периодов хранения данных – таблицы изменений продолжат расти, пока данные изменений не будут очищены. Это ведет к общим архитектурным размышлениям о том, что нужно отслеживать и сколько хранить. Важные вопросы, которые стоит учесть, включают в себя следующие.
Список требуемых столбцов для экземпляра сбора. По мере сбора большего числа столбцов, больше данных изменений вставляется в таблицы изменений.
Объем пространства на диске, используемого таблицами изменений.
Частота, с которой работает процесс, потребляющий данные изменений. Имейте в виду, что данные не могут быть удалены, если они еще не были использованы.
Частота, с которой работает процесс очистки, – данных изменений может быть так много, что процесс, удаляющий их, может, например, работать только по выходным, потому что иначе он создает слишком большой журнал транзакций.
Сбор данных изменений может быть установлен на простое отслеживание изменений в таблице или отслеживание части столбцов в таблице. Использование только части может быть полезно, если часть несущественных столбцов – очень широкие столбцы varchar, или столбцы больших двоичных объектов (BLOB), таких как текст, изображение или XML); иначе пространство, используемое таблицей изменений может очень быстро стать неудобно большим.
Учитывая повышенный потенциал использования пространства на диске, положение таблицы изменений в файловой группе можно установить при включении сбора данных изменений. Это упрощает управление пространством лежащего в основе диска и значит, что все данные об изменениях потенциально могут быть сохранены в томе с менее затратным уровнем RAID, чем основная база данных. Кроме того, хотя параметры задачи очистки применяются ко всем экземплярам сбора, отдельный экземпляр сбора можно очистить отдельно и в любое время, если пространство на диске становится проблемой. Использование пространства диска можно легко отслеживать, используя sp_spaceused на таблицах сбора.
Собственно строка вписанная в таблицу изменений содержит метаданные о транзакции (номер последовательности журнала фиксации – LSN), а также порядок внутри транзакции, в котором произошло изменение, что за операция производилась, битовую маску измененных столбцов и значения собственно столбца.
Изменения DDL неограниченны, когда включен сбор данных изменения. Однако они могут возыметь некоторый эффект на собранных данных изменений в случае добавления или сброса столбцов. Если отслеживаемый столбец сброшен, во всех дальнейших записях в экземпляре сбора для этого экземпляра будет стоять NULL. Если столбец добавлен, он будет проигнорирован экземпляром сбора. Другими словами, форма экземпляра сбора определяется в момент его создания.
Если требуются изменения столбцов, то возможно создать другой экземпляр сбора для таблицы (до максимума в два экземпляра сбора на таблицу) и позволить потребителям данных изменений перейти на новую схему таблицы. Но при этом следует соблюдать осторожность, поскольку два экземпляра сбора для отслеживаемой таблицы означают удвоенные ввод/вывод, запись в журнал и потребление пространства диска.
Не углубляясь слишком далеко, данные извлекаются из таблиц изменений с помощью описанных мною функций. Функции берут начальный номер последовательности журнала и конечный номер последовательности журнала, предоставлены также и другие функции, позволяющие преобразовать обычное время в номер последовательности журнала . При извлечении обновлений можно даже указать, нужно ли увидеть предыдущее и последующее значения или только предыдущее. Демонстрационный ролик, где я использую сбор данных изменений, доступен по адресу www.technetmagazine.com/video.
Как работает отслеживание изменений
Как я уже упоминал, отслеживание изменений – это синхронный процесс, который куда менее сложен, чем сбор данных изменений. Это часть транзакции, которая вносит изменение в строку в отслеживаемой таблицы и тот факт, что строка изменилась, отслеживается в отдельной таблице. Данная таблица – это то, что называется внутренней таблицей, и ее имя с местом хранения нельзя контролировать. Я не считаю это проблемой, поскольку в этой таблице должно быть гораздо меньше данных, чем в таблице изменений, используемой для сбора данных изменений. Но, как я сейчас объясню, проблемы с пространством на диски все же возможны.
Тот факт, что отслеживание изменений выполняется синхронно, означает, что внутри каждой транзакции происходит гораздо меньшей дополнительной обработки, изменяющей отслеживаемую таблицу. Воздействие на производительность подобно тому, что имеет место при существовании на таблице некластеризованного индекса, который необходимо изменять с каждым изменением таблицы. Сами транзакции также отслеживаются при их последовательной фиксации во внутренней таблице sys.syscommittab.
Отслеживание изменений включается и отключается с использованием обычного синтаксиса ALTER DATABASE и ALTER TABLE и следует той же модели, что и сбор данных изменений, где оно должно быть включено на уровне базы данных перед включением на уровне таблицы. Последовательность операций будет выглядеть примерно следующим образом:
ALTER DATABASE AdventureWorks2000 SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
GO
USE AdventureWorks2000;
GO
ALTER TABLE Person.Person ENABLE CHANGE_TRACKING
WITH (TRACK_COLUMNS_UPDATED = ON);
GO
Требуемые разрешения для включения отслеживания изменений на уровнях базы данных и таблицы также отличаются от требуемых для включения сбора данных изменений: db_owner и владельца таблицы, соответственно. Когда отслеживание изменений включается на уровне базы данных, можно установить период хранения, а также указать, будут ли данные изменений очищаться автоматически. Период хранения по умолчанию – 2 дня, с максимумом в 90 дней и минимумом в одну минуту.
Автоматическая очистка также включается по умолчанию. При внесении изменений в эти параметры, необходимо оценить те же приоритеты, о которых я говорил применительно к сбору данных изменений, – что важнее для приложения: пространство на диске или производительность.
По умолчанию для каждой строки собирается лишь факт ее изменения. Это выполняется путем создания заметки из первичного ключа изменившейся строки (что означает невозможность отслеживать изменения на таблице без первичного ключа), вместе с номером версии (после того как на базе данных включено отслеживание изменений, устанавливается номер версии, что позволяет определить порядок операций) и тип операции, выполнившей изменение. Как вариант, можно также отследить, какие столбцы изменились, это требует 4 байт на изменившийся столбец.
Наблюдение за пространством на диске несколько отличается от отслеживания изменений, поскольку данные об изменениях хранятся во внутренних таблицах. Чтобы найти имена используемых внутренних таблиц, просто используйте представление каталога системы sys.internal_tables:
SELECT [name] FROM sys.internal_tables
WHERE [internal_type_desc] = 'CHANGE_TRACKING';
GO
Затем передайте имя в sp_spaceused, чтобы увидеть, сколько используется дискового пространства.
В отличие от сбора данных изменений, когда включено отслеживание изменений, существуют ограничения на DDL, который можно выполнять на отслеживаемой таблице. Наиболее заметным ограничением является невозможность как-либо изменять основной ключ. Другое ограничение, заслуживающее упоминания здесь, заключается в том, что ALTER TABLE SWITCH потерпит неудачу, если на любой из затронутых таблиц было включено отслеживание изменений. Это, скорее всего, вызывается тем фактом, что не имеет смысла автоматически начинать или удалять отслеживание изменений для отключаемого из отслеживаемой, разбитой на разделы, таблицы, раздела или отслеживаемой таблицы, включаемой в разбитую на разделы таблицу, соответственно.
Изменения извлекаются из внутренних таблиц изменений с использованием новой функции CHANGETABLES (CHANGES …). Она принимает имя отслеживаемой на предмет изменений таблицы плюс номер версии с предыдущего раза, когда она использовалась, и возвращает информацию о всех строках, изменившихся с прошлого раза. Существуют различные функции для поиска текущей и наиболее старой допустимой версии. Приложение может затем использовать возвращенную информацию для запроса таблицы, отслеживаемой на предмет изменений, чтобы получить реальные значения столбцов. Это, само собой, многоэтапный процесс – сперва получается текущая версия, затем эта версия используется для запроса отслеживания изменений и затем собственно таблицы запрашиваются на предмет данных столбцов, соответствующих этой версии.
В постоянно изменяющейся системе возможно получить непоследовательные или неверные результаты, если не поддерживать какого-либо рода неизменное представление версии, данных изменений и собственно данных столбцов. Чтобы сделать это, можно использовать изоляцию снимка и поместить многоэтапный процесс в прямую транзакцию. Этот способ работает эффективно, но имеет потенциальные недостатки. Изоляция снимка может сказаться на производительности рабочей нагрузки и влияет на производительность и использование пространства в tempdb. Дополнительные сведения об этом можно найти по адресу technet.microsoft.com/library/cc280358.
Заключение
Рис. 4 предоставляет попунктовое сравнение отслеживания изменений и сбора данных изменений, позволяя получить лучшее представление о серьезных различиях, актуальных для администраторов баз данных. Из таблицы можно увидеть, что сбор данных изменений намного тяжеловеснее отслеживания изменений. Он требует большего внимания при принятии решений о том, что отслеживать, в силу потенциала к быстрому росту размера таблицы отслеживания, если, скажем, отслеживаемая таблица содержит столбцы BLOB или очень широкие строки. Возможны также проблемы с управлением журналом транзакций, поскольку журнал не будет обрезаться, пока средство чтения журнала не собрало записи из него.
Рис. 4. Сравнение отслеживания изменений и сбора данных изменений.

Но и отслеживание изменений не лишено своих требований. Например, ему необходим первичный ключ и при его применении настоятельно рекомендуется использовать изоляцию снимков. Изоляция снимков сама по себе может добавить рабочей нагрузке существенных издержек ресурсов и требует гораздо более аккуратного управления tempdb.
Существует одна дополнительная проблема, которую необходимо решать разработчикам и администраторам баз данных: аварийное восстановление. Хотя подробный рассказ о нем выходит за рамки этой статьи, тема аварийного восстановления слишком важна, чтобы не упомянуть о ней.
Обе функции хорошо работают с BACKUP и RESTORE. Проблема возникает тогда, когда база данных восстанавливается и по сути оказывается отброшенной назад во время. Как должны вести себя приложение/система в целом? Специальные решения, разработанные для отслеживания изменений, также сталкиваются с этой проблемой, и о ней следует помнить при использовании SQL Server 2008.
Как и всегда, убедитесь в том, что прочли всю доступную документацию (technet.microsoft.com/library/bb418491) и любые существующие технические документы, перед тем, как браться за работу над проектом, включающим новые функции отслеживания изменений. В первую очередь следует узнать, не могут ли быть применимы к вашему случаю какие-либо проблемы, не освещенные в этой статье. Следует также узнать подробности о новых пакетах обновления и динамических административных представлениях для наблюдения.
В целом эти новые функции являются огромным шагом вперед по сравнению с предыдущими методами отслеживания изменений в данных. Теперь, когда они существуют, можно быть уверенным, что разработчики пожелают использовать их в управляемых читателями решениях.
С ними связаны важные проблемы настройки и управления и я надеюсь, что эта статья дала читателям основательный обзор технологий, могущий позволить им предугадать некоторые из описанных мной проблем и подготовиться к ним.
|