Администраторы баз данных SQL Server по всему миру сталкиваются с проблемой, которая кажется вечной: устранением неполадок, основной объем которого осуществляется для обнаружения тех или иных проблем с производительностью. Даже наиболее тщательно сконструированная и протестированная система приложений испытывает изменения с течением времени, что может привести к значительным проблемам с производительностью.
Например, может измениться рабочая нагрузка (такая, как число параллельных пользователей, выполняемые запросы и выполняемые в конце месяца отчеты), объем обрабатываемых данных может возрасти, оборудование, на котором работает система, может измениться (например, в плане числа ядер процессоров, объеме доступной памяти сервера и возможностей подсистемы ввода/вывода) и на систему могут быть возложены новые параллельные рабочие нагрузки (такие, как транзакционная репликация, зеркальное отображение баз данных и запись данных об изменениях).
Но проблемы этим не исчерпываются. При разработке и тестировании системы приложений часто обнаруживаются непредвиденные проблемы с ее проектом, которые также приходится устранять. Очевидно, что вне зависимости от того, когда в жизненном цикле приложения обнаружена проблема, необходимо выполнение устранения неполадок, для определения причины и решения.
Комплексная система приложений будет иметь много программных и аппаратных компонентов, которые могут потребовать анализа, но здесь меня интересует один из них – SQL Server. Если не касаться различных методологий устранения проблем производительности (разговор о которых выйдет далеко за рамки этой статьи), каковы средства, необходимые для устранения неполадок в SQL Server?
Устранение неполадок в SQL Server 2005
В новейших выпусках SQL Server существенно вырос выбор средств, доступных для устранения неполадок производительности. В SQL Server всегда были доступны многочисленные команды DBCC (команда консоли базы данных), для представления подробностей того, что происходит в различных частях механизма базы данных. Кроме того, есть профилировщик SQL и программное использование базового механизма трассировки SQL.
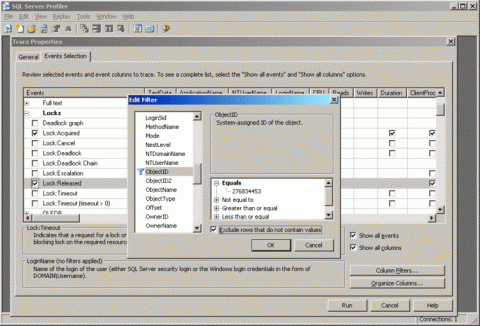
Хотя SQL Server постоянно предлагал улучшения в области устранения неполадок, у этих вариантов имеются определенные проблемы. Послеобработка данных, выдаваемых DBCC, неуклюжа, из-за необходимости сбрасывать результаты во временную таблицу, прежде чем с ними можно будет что-нибудь сделать. И выполнение трассировки/профилировщика SQL может вызвать падение производительности в случае неудачной настройки (такой как отслеживание всех событий получения и отдачи блокировки на занятой системе, при которой забыто про фильтровку столбцов DatabaseId и ObjectId события). Снимок экрана на рис. 1 показывает диалог, используемый для настройки фильтра под новую трассировку.

Рис. 1. Настройка фильтра в профилировщике SQL Server 2008
SQL Server 2005 добавил динамические представления и функции управления (совместно известные как DMV) в качестве способа получения информации от механизма базы данных. DMV заместили некоторые команды DBCC, системные таблицы и хранимые процедуры, а также предоставили много новых областей работы с механизмом. Эти DMV являются компонуемыми командами с широкими возможностями – их можно использовать в комплексных операторах T-SQL, выполняющих фильтрацию и постобработку результатов DMV.
Например, код показанный на рис. 2 возвращает лишь показатели фрагментации и плотности страницы (оба округленные) конечного уровня всех индексов в базе данных, с фильтром на уровне фрагментации. Это нельзя было сделать просто, используя мою старую команду DBCC SHOWCONTIG. (Дополнительные сведения о DMV см. в "Dynamic Management Views and Functions (Transact-SQL) («Представления и функции динамического управления (Transact-SQL)»)". Вдобавок, SQL Server 2005 добавил ряд других функций, которые можно было использовать для устранения неполадок, включая триггеры DDL (языка определения данных) и уведомления о событиях.
Использование DMV для получения впечатляющих результатов
SELECT
OBJECT_NAME (ips.[object_id]) AS 'Object Name',
si.name AS 'Index Name',
ROUND (ips.avg_fragmentation_in_percent, 2) AS 'Fragmentation',
ips.page_count AS 'Pages',
ROUND (ips.avg_page_space_used_in_percent, 2) AS 'Page Density'
FROM sys.dm_db_index_physical_stats (
DB_ID ('SQLskillsDB'), NULL, NULL, NULL, 'DETAILED') ips
CROSS APPLY sys.indexes si
WHERE
si.object_id = ips.object_id
AND si.index_id = ips.index_id
AND ips.index_level = 0 -- only the leaf level
AND ips.avg_fragmentation_in_percent > 10; -- filter on fragmentation
GO
Различные группы внутри корпорации Майкрософт также предоставили полезные средства устранения проблем производительности, такие как служебная программы SQLdiag, служебные программы RML для SQL Server, Отчеты панели мониторинга производительности SQL Server 2005 и DMVStats. Существует также провайдер отслеживания событий для Windows (ETW) для SQL Server 2005, позволяющий выполнять интеграцию событий SQL Trace с событиями из других частей Windows.
Хотя SQL Server 2005 добился большого продвижения в повышении возможностей администраторов баз данных по устранению неполадок в механизме баз данных, сохранялось множество сценариев, в которых эффективное устранение неполадок было почти невозможным для администратора. В одном часто приводимом примере, некоторые запросы использовали чрезмерные объемы ресурсов ЦП, но DMV не предоставляли достаточно информации, чтобы указать, какие незапланированные запросы были в этом виновны. Но, в отличие от SQL Server 2005, SQL Server 2008, может отреагировать на такие ограничения с помощью новой функции, именуемой расширенными событиями SQL Server.
Расширенные события
Возможности системы расширенных событий выходят далеко за пределы возможностей любой предыдущего механизма отслеживания событий и устранения неполадок, предоставленного SQL Server. По моему мнению, выделяющимися особенностями системы расширенных событий являются следующие:
События запускаются синхронно, но могут обрабатываться синхронно или асинхронно.
Любая цель может потреблять любое событие и любое действие может быть связано с любым событием, делая возможной углубленную систему наблюдения.
«Умные» предикаты позволяют создавать сложные правила, используя булеву логику.
Сеансы расширенных событий можно полностью контролировать, используя Transact-SQL.
За важным для производительности кодом можно наблюдать, не влияя на производительность.
Прежде чем идти дальше, я потрачу немного времени на то, чтобы определить часть новых терминов.
Событие Событие – это определенная точка в коде. Некоторыми из примеров являются точка, на которой оператор T-SQL завершил исполняться или точка, на которой завершено получение блокировки. Каждое событие имеет определенные полезные данные (набор столбцов, возвращаемых событием) и определяется с использованием модели ETW (где каждое событие возвращает канал и ключевое слово как часть полезных данных), чтобы позволить интеграцию с ETW. SQL Server 2008 первоначально поставлялся с 254 ожидаемыми событиями и, с течением времени, ожидается добавление новых.
Список определенных событий можно увидеть, используя следующий код:
SELECT xp.[name], xo.*
FROM sys.dm_xe_objects xo, sys.dm_xe_packages xp
WHERE xp.[guid] = xo.[package_guid]
AND xo.[object_type] = 'event'
ORDER BY xp.[name];
А полезную нагрузку для события можно найти, используя этот код:
SELECT * FROM sys.dm_xe_object_columns
WHERE [object_name] = 'sql_statement_completed';
GO
Отметьте, что у системы расширенных событий имеется исчерпывающий набор информационных DMV, которые описывают все события, цели и так далее. Дополнительные сведения см. в "SQL Server Extended Events Dynamic Management Views («Динамические представления управления расширенных событий SQL Server»)".
Предикаты Предикаты являются методом, используемым для фильтрации событий с использованием набора логических правил, перед потреблением событий. Предикаты могут быть простыми, такими как проверка, является ли один из столбцов, возвращенных в полезной нагрузке, события, определенным значением (например, фильтрация событий получения блокировки по идентификатору объекта).
Они также предоставляют некоторые дополнительные возможности, такие, как отсчет числа случаев определенного события в течении сеанса и допуск потребления определенного события только после динамического обновления самого предиката, чтобы предотвратить потребление событий, содержащих похожие данные.
Предикаты могут быть написаны с использованием булевой логики, для скорейшего их замыкания. Это позволяет минимизировать объем синхронной обработки данных, выполняемой перед определением, будет ли событие потреблено или нет.
Действие Действие – это набор команд, выполняемых синхронно, перед потреблением события. Любое действие может быть привязано к любому событию. Обычно они собирают дополнительные данные для присоединения к полезной нагрузке события (такой, как стек T-SQL или план исполнения запроса) или выполняют определенные вычисления, присоединяемые к полезной нагрузке события.
Поскольку действия могут быть ресурсозатратны, действия для события выполняются только после оценки любого из предикатов – синхронное выполнение действия не имело бы смысла, если бы в этот момент определилось, что событие не будет потреблено. Список заранее определенных действий можно найти, используя следующий код:
SELECT xp.[name], xo.*
FROM sys.dm_xe_objects xo, sys.dm_xe_packages xp
WHERE xp.[guid] = xo.[package_guid]
AND xo.[object_type] = 'action'
ORDER BY xp.[name];
Цель Цель просто предоставляет способ потребления событий и любая цель может потребить любе событие (или, по крайней мере, избавиться от него, если цели нечего с ним делать – например, в случае цели аудита, получившей не относящееся к аудиту событие). Цели могут потреблять события синхронно (например, код, запустивший событие, ждет потребления события) или асинхронно.
Цели охватывают диапазон от простых потребителей, таких как файлы событий и кольцевые буферы, до более сложных потребителей, обладающих возможностью выполнять сопоставление событий. Список доступных целей можно найти, используя следующий код:
SELECT xp.[name], xo.*
FROM sys.dm_xe_objects xo, sys.dm_xe_packages xp
WHERE xp.[guid] = xo.[package_guid]
AND xo.[object_type] = 'target'
ORDER BY xp.[name];
Дополнительные сведения о целях см. в "SQL Server Extended Events Targets («Цели расширенных событий SQL Server»)".
Пакет Пакет – это контейнер, определяющий объекты расширенных событий (такие, как события, действия и цели). Пакет содержится внутри описываемого им модуля (такого, как исполняемый файл или DLL), как показано на рис. 2.

Рис. 2. Отношения между модулями, пакетами и объектами расширенных событий
Когда пакет регистрируется с помощью механизма расширенны событий, все определенные им объекты становятся доступными для использования. Дополнительные сведения о пакетах и полный список терминов расширенных событий можно найти в "SQL Server Extended Events Packages («Пакеты расширенных событий SQL Server»)".
Сеанс Сеанс – это способ связывания объектов расширенных событий вместе для обработки – событие с действием, которое будет потреблено целью. Сеанс может связывать объекты из любых зарегистрированных пакетов и любое число сеансов могут использовать одно и то же событие, действие и так далее. То, какие сеансы расширенных событий определены, можно увидеть, используя следующий код:
SELECT * FROM sys.dm_xe_sessions;
Go
Сеансы создаются, удаляются, изменяются, останавливаются и запускаются с использованием команд T-SQL. Как можно себе представить, это обеспечивает значительную гибкость, включая даже возможность динамически изменить сеанс, основываясь на программном анализе данных, записанных самим сеансом. Дополнительные сведения о сеансах см. в "SQL Server Extended Events Sessions («Сеансы расширенных событий SQL Server»)".
Соображения производительности
При сборке сеанса расширенных событий с использованием CREATE EVENT SESSION, существует ряд параметров, на правильную настройку которых следует обратить внимание, поскольку они могут непреднамеренно повлиять на производительность. Первое решение заключается в том, должны ли события потребляться синхронно или асинхронно. Как и можно ожидать, синхронные цели оказывают большее влияние на производительность отслеживаемого кода, чем асинхронные цели.
Как я объяснил выше, когда событие потребляется синхронно, код, запустивший событие, должен ждать, пока событие не потреблено. Очевидно, что если потребление события является сложным процессом, это может замедлить работу кода.
Например, на занятой системе, обслуживающей тысячи мелких транзакций в секунду, синхронное потребление события sql_statement_completed с действием для записи плана запроса, скорее всего, окажет негативное влияние на производительность. Кроме того, помните, что предикаты всегда исполняются синхронно, так что следует позаботиться о том, чтобы не создавать чрезмерно сложных предикатов для событий, запускаемых важным для производительности кодом.
С другой стороны, потреблять события синхронно может быть необходимо. Простейшим способом подсчета того, сколько раз произошло определенное событие, будет использование цели synchronous_event_counter.
Вторая вещь, которую необходимо обдумать, состоит в том, как настроить буферизацию событий, если решено использовать асинхронные цели. Объем памяти, доступный по умолчанию для буферизации событий – 4 МБ. Задержка диспетчера между запуском события и его последующим потреблением целью, по умолчанию составляет 30 секунд. Если, скажем, необходимо предоставлять какие-то статистики события каждые 10 секунд, то необходимо подправить задержку.
К параметрам буферизации событий привязано то, как следует разбивать память, используемую для буферизации событий. По умолчанию создается набор буферов для всего экземпляра. На компьютерах SMP (симметричный микропроцессор) и NUMA (доступ к неоднородной памяти) это может привести к проблемам с производительностью, поскольку компьютерам придется ждать доступа к памяти.
В третьих, следует подумать о том, как желательно обрабатывать потерю событий. При определении сеанса расширенных событий, можно указать, могут ли события быть «потеряны». Это значит, что при недостаточности памяти для буферизации события, оно просто удаляется. Установки по умолчанию позволяют сбрасывать единичные события, но можно также позволить потерю целых буферов событий (для сеансов, где буферы событий заполняются очень быстро) и даже указать, что события не могут теряться.
Последний вариант следует использовать с большой осторожностью, поскольку он заставляет код, запустивший событие, ждать, пока не появится достаточно памяти буфера, чтобы сохранить событие. Установка этого параметра почти всегда оказывает отрицательное влияние на производительность. Отметьте, что если этот вариант случайно включен, сервер должен сохранить способность к реагированию в достаточной степени, чтобы отключить его.
Обычно эти параметры стоит обдумывать вместе. И здесь я не могу дать общих рекомендаций, за исключением того, что им следует уделить внимание, чтобы не столкнуться с проблемами производительности. Дополнительные сведения об этих параметрах можно найти в "CREATE EVENT SESSION (T-SQL)".
Жизнь события
После того, как сеанс расширенных событий был определен и запущен, обработка продолжается как обычно, пока отслеживаемый код не сталкивается с событием. Действия, выполняемые системой расширенных событий, обрисованы на рис. 3. Порядок их таков:
Выполняется проверка, чтобы увидеть наблюдает ли за событием какой-то из сеансов расширенных событий. Если нет, контроль возвращается коду, содержащему событие и обработка продолжается.
Определяется полезная нагрузка события и вся требуемая для нее информация собирается в памяти – другими словами, конструируется полезная нагрузка.
Если для события определены предикаты, они исполняются. На этом этапе, предикат может указать, что событие не следует потреблять. Если это так, контроль возвращается коду, содержащему событие и обработка продолжается.
Теперь система знает, что событие будет потреблено, так что она исполняет действия, связанные с событием. Теперь у события имеется завершенная полезная нагрузка и оно готово к потреблению.
Событие выдается синхронным целям, если таковые есть.
Если имеются асинхронные цели, событие буферизуется для последующей обработки.
Контроль возвращается коду, содержащему событие и обработка продолжается.
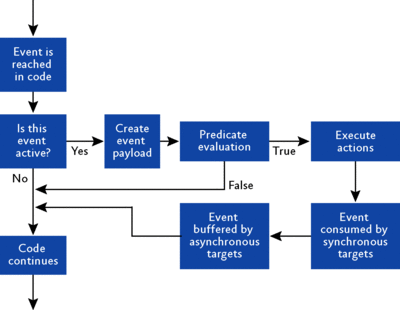
Рис. 3. Жизненный цикл события расширенных событий
Как я упомянул ранее, при создании сеанса события следует быть осторожным, чтобы синхронные действия или буферизация для асинхронных целей не повлияли бы на производительность отслеживаемого кода.
Использование расширенных событий
Электронная документация SQL Server 2008 включает два примера использования расширенных событий: "Практическое руководство: определение запросов, удерживающих блокировки" и "Практическое руководство: поиск объектов, на которых взято наибольшее число блокировок".
Я хотел бы разобрать пример настройки сеанса расширенных событий и проанализировать результаты. Как я узнал, когда начал использовать расширенные события в конце 2007 года, собрать простой сеанс очень просто (с помощью нехитрых операторов DDL T-SQL), но анализ результатов – нетривиальная задача.
Результаты представляются в XML, что первоначально удивило меня, прежде чем я осознал, что огромность количества возможных комбинаций событий и действий, которые могут быть собраны за один сеанс действительно означает отсутствие иного реального выбора для хранения настолько расширяемой схемы.
Надо заметить, я был разработчиком в группе подсистемы хранилища SQL Server в течение многих лет и считаю себя высокопрофессиональным программистом C, C++ и сборок, но мне пришлось провести несколько часов, разбираясь в коде, необходимом для программного извлечения полей полезных нагрузок из данных XML. Я не пытаюсь отговорить читателей от использования расширенных событий; я просто предупреждаю, что тем, у кого нет опыта работы с данными XML, придется потратить некоторые усилия на обучение ему, прежде чем появятся результаты.
Вот мой сценарий: я администратор базы данных, использующий функцию регулятора ресурсов в SQL Server 2008, чтобы изолировать различные группы в моей компании на одном из рабочих серверов. Я создал два пула регулятора ресурсов (разработки и маркетинга) для представления использования данного сервера каждой из групп. Регулятор ресурсов позволяет мне ограничивать использование ЦП и памяти на исполнение запросов каждым пулом, но не объем используемых ими ресурсов ввода/вывода. Так что мне хотелось бы установить механизм возвратных платежей, помогающий компенсировать затраты на установку новой сети, выставляя каждой группе счет за использование ввода/вывода на этом сервере.
Я предполагаю, что простейшим способом инициализации записи информации ввода/вывода будет делать это, когда завершается работа любого оператора T-SQL и я знаю, что в пакете package0 имеется событие, именуемое sql_statement_completed. Так какие же данные собираются в полезной нагрузке события?
Исполнение следующего кода даст мне список всех данных, включая как чтения, так и записи:
SELECT [name] FROM sys.dm_xe_object_columns
WHERE [object_name] = 'sql_statement_completed';
GO
Я не думаю, что это физические чтения и записи (когда данные считываются с диска, а не просто с памяти в пуле буфера, или записываются на него) но они дают мне представление о пропорции ресурсов ввода/вывода, используемых каждой группой.
Теперь мне нужно вычислить, какая группа исполнила определенный оператор T-SQL, так что нужно действие, которое сказало бы мне это. Исполнение кода дает мне список всех действий, которые я могу предпринять при запуске события включая действие, собирающее session_resource_pool_id в пакете sqlserver:
SELECT xp.[name], xo.*
FROM sys.dm_xe_objects xo, sys.dm_xe_packages xp
WHERE xp.[guid] = xo.[package_guid]
AND xo.[object_type] = 'action'
ORDER BY xp.[name];
Я могу получить список пулов ресурсов, определенный для регулятора ресурсов и соотнести его с идентификаторами, собранными моим сеансом расширенных событий. Теперь я готов определить мой сеанс. Отметьте, что когда я исполняю этот код, он сперва проверит, существует ли сеанс события с тем же именем. Если таковой будет найден, он прервет сеанс. Вот код:
IF EXISTS (
SELECT * FROM sys.server_event_sessions
WHERE name = 'MonitorIO')
DROP EVENT SESSION MonitorIO ON SERVER;
GO
CREATE EVENT SESSION MonitorIO ON SERVER
ADD EVENT sqlserver.sql_statement_completed
(ACTION (sqlserver.session_resource_pool_id))
ADD TARGET package0.ring_buffer;
GO
Затем он создает новый сеанс, с единственным событием sql_statement_completed, которое также выполняет session_resource_pool_id action, записывая все в кольцевой буфер, пока я все еще работаю с прототипом. (В рабочей среде, я скорее всего выбрал бы целью асинхронный файл.)
Для начала моего сеанса, мне нужно исполнить такой код:
ALTER EVENT SESSION MonitorIO ON SERVER
STATE = START;
GO
Теперь он работает.
После имитации некоторого объема деятельности групп маркетинга и разработки, я готов к анализу результатов сеанса. Данный код извлечет данные из кольцевого буфера:
SELECT CAST(xest.target_data AS XML) StatementData
FROM sys.dm_xe_session_targets xest
JOIN sys.dm_xe_sessions xes ON
xes.address = xest.event_session_address
WHERE xest.target_name = 'ring_buffer'
AND xes.name = 'MonitorIO';
GO
Однако, он извлекает данные как одно большое значение XML. Если мне нужно разбить его на составляющие, я могу использовать код, показанный на рис. 5.
Разбиение данных XML
SELECT
Data2.Results.value ('(data/.)[6]', 'bigint') AS Reads,
Data2.Results.value ('(data/.)[7]', 'bigint') AS Writes,
Data2.Results.value ('(action/.)[1]', 'int') AS ResourcePoolID
FROM
(SELECT CAST(xest.target_data AS XML) StatementData
FROM sys.dm_xe_session_targets xest
JOIN sys.dm_xe_sessions xes ON
xes.address = xest.event_session_address
WHERE xest.target_name = 'ring_buffer'
AND xes.name = 'MonitorIO') Statements
CROSS APPLY StatementData.nodes ('//RingBufferTarget/event') AS Data2 (Results);
GO
Это работает, но дает мне одну строку результатов на каждое записанное событие. Это не то что бы великолепный формат, кроме того, мне хотелось бы получить сводный вывод, так что я решил использовать производную таблицу, как можно увидеть на рис. 6.
Получение сводного вывода
SELECT DT.ResourcePoolID,
SUM (DT.Reads) as TotalReads,
SUM (DT.Writes) AS TotalWrites
FROM
(SELECT
Data2.Results.value ('(data/.)[6]', 'bigint') AS Reads,
Data2.Results.value ('(data/.)[7]', 'bigint') AS Writes,
Data2.Results.value ('(action/.)[1]', 'int') AS ResourcePoolID
FROM
(SELECT CAST(xest.target_data AS XML) StatementData
FROM sys.dm_xe_session_targets xest
JOIN sys.dm_xe_sessions xes ON
xes.address = xest.event_session_address
WHERE xest.target_name = 'ring_buffer'
AND xes.name = 'MonitorIO') Statements
CROSS APPLY StatementData.nodes ('//RingBufferTarget/event') AS Data2 (Results)) AS DT
WHERE DT.ResourcePoolID > 255 –- only show user-defined resource pools
GROUP BY DT.ResourcePoolID;
GO
Уф! Здесь явно встречается замысловатый код, но он работает хорошо. Так что теперь я получил желаемые результаты. Взгляните на результаты запроса по моим тестовым данным, показанные на рис. 7. Выходные данные моего запроса
ResourcePoolID TotalReads TotalWrites
256 3831 244
257 5708155 1818
Я знаю, что пул ресурсов 256 относится к группе маркетинга, а 257 – к группе разработки, так что эти числа имеют смысл в плане того, насколько интенсивную работу с базой данных я ожидаю от групп в моей компании. Мне не удалось бы получить эти результаты настолько просто, если б я не использовал расширенные события.
И, наконец, мне нужно остановить сеанс, используя следующий код:
ALTER EVENT SESSION MonitorIO ON SERVER
STATE = STOP;
GO
Чтобы увидеть больше из того, о чем я говорю в плане вывода на каждой стадии данного примера, загляните в демонстрационный ролик, прилагающийся к данной статье. Его можно найти на technetmagazine.com/video.
Сеанс расширенных событий system_health
SQL Server 2008 поставляется с заранее определенным сеансом, который установлен на выполнение по умолчанию и именуется сеансом system_health. Создание этого сеанса было идеей группы поддержки продукта и он отслеживает информацию, обычно используемую ими для отладки клиентских систем, например в случае взаимоблокировки или серьезной ошибки. Этот сеанс создается и запускается как часть процесса установки для экземпляра SQL Server 2008 и он отслеживает события в кольцевом буфере, так что он не потребляет слишком много памяти.
Чтобы увидеть, что содержит кольцевой буфер, можно использовать следующий код:
SELECT CAST (xest.target_data AS XML)
FROM sys.dm_xe_session_targets xest
JOIN sys.dm_xe_sessions xes ON
xes.address = xest.event_session_address
WHERE xes.name = 'system_health';
GO
Блог поддержки SQL службы поддержки Майкрософт содержит более подробные сведения о том, что отслеживается этим сеансом.
Заключение
Мне сказали, что группа SQL Server планирует, в будущем, добавить в sqlserver.exe много новых событий. Фактически, число подскочило со 165 в CTP-версии февраля 2007 года (представление сообществу) до 254 в RTM-версии (окончательная первоначальная).
Стоит также обратить внимание на некоторые действительно интересно выглядящие события, например события записи данных изменений (которое я осветил в своей статье "Отслеживание изменений в корпоративной базе данных" из выпуска журнала TechNet Magazine за ноябрь 2008 года), сжатия данных и разбиения страниц индексов. Разбиение страниц индексов выглядит многообещающим способом выяснения того, какие индексы накапливают подрывающую производительность фрагментацию, без необходимости периодически выполнять DMV sys.dm_db_index_physical_stats на всех индексах.
В целом, новая система расширенных событий делает возможным довольно изощренное наблюдение, которое ранее не было возможно. Хотя она требует некоторого обучения, чтобы познакомиться с анализом XML, необходимым для получения данных, преимущества новой системы намного перевешивают трудности изучения новых конструкций кода.
|